
))
“How Well Does RL Scale?” by Toby_Ord
Manage episode 516788577 series 3364758
المحتوى المقدم من LessWrong. يتم تحميل جميع محتويات البودكاست بما في ذلك الحلقات والرسومات وأوصاف البودكاست وتقديمها مباشرة بواسطة LessWrong أو شريك منصة البودكاست الخاص بهم. إذا كنت تعتقد أن شخصًا ما يستخدم عملك المحمي بحقوق الطبع والنشر دون إذنك، فيمكنك اتباع العملية الموضحة هنا https://ar.player.fm/legal.
This is the latest in a series of essays on AI Scaling.
You can find the others on my site.
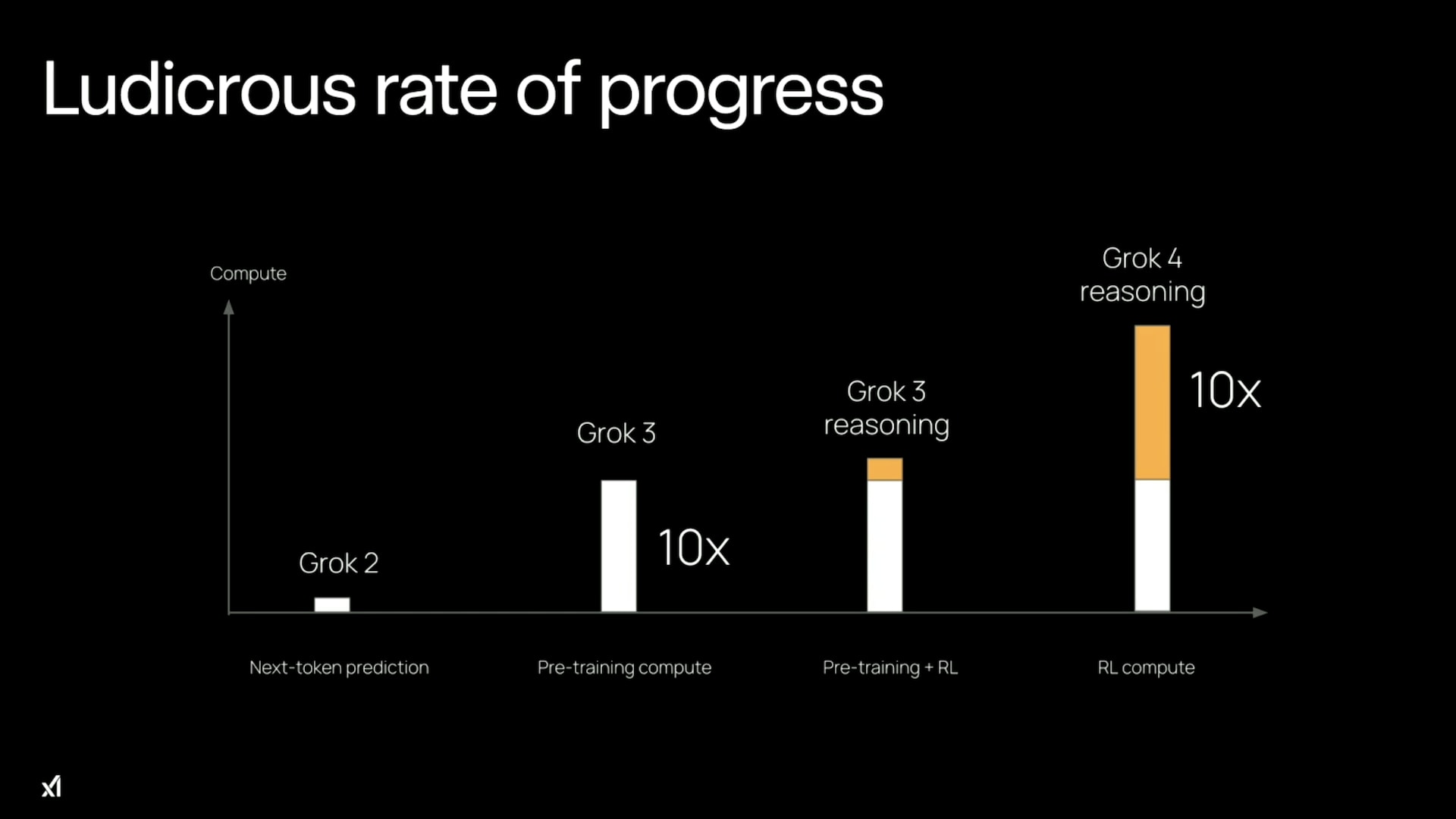
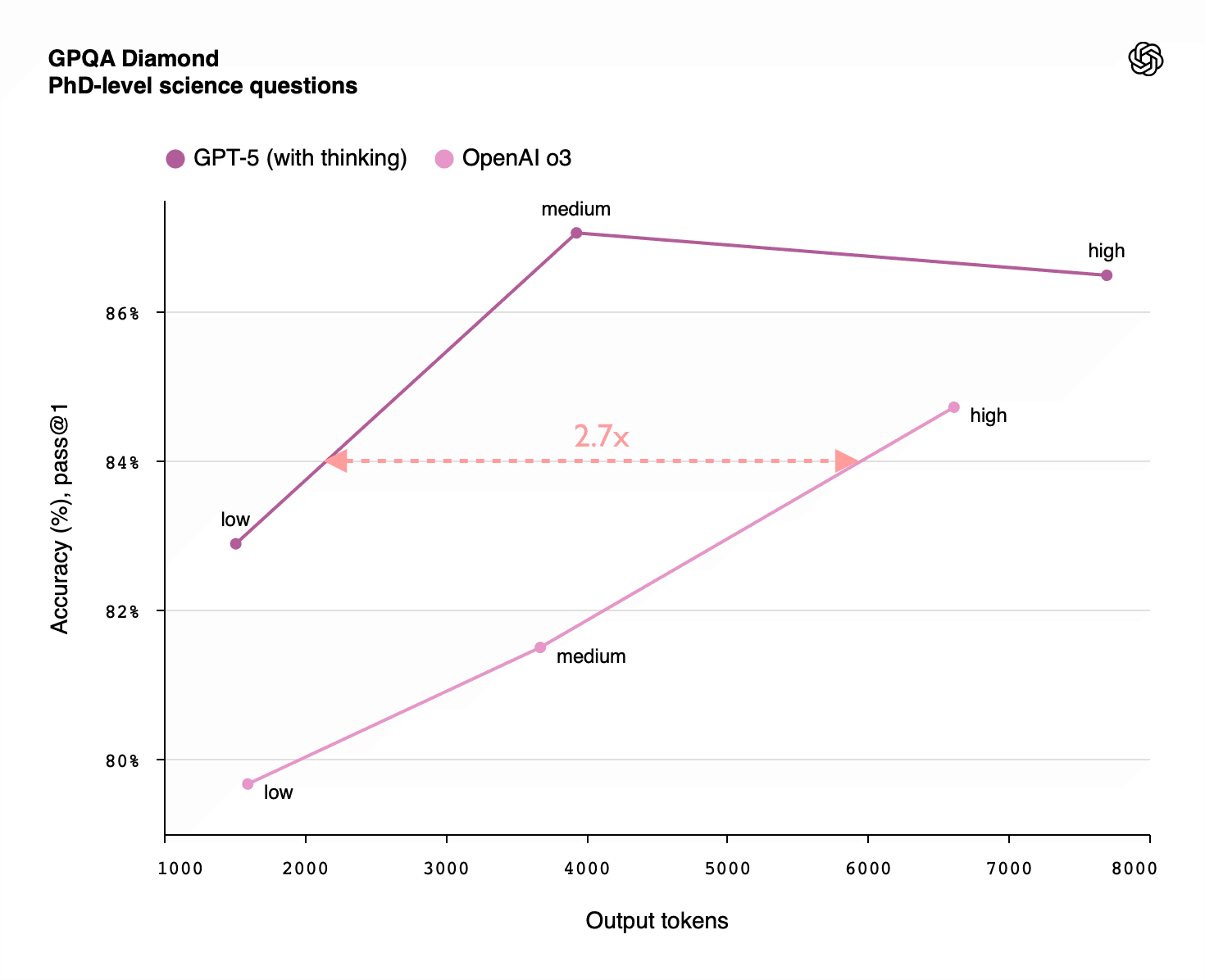
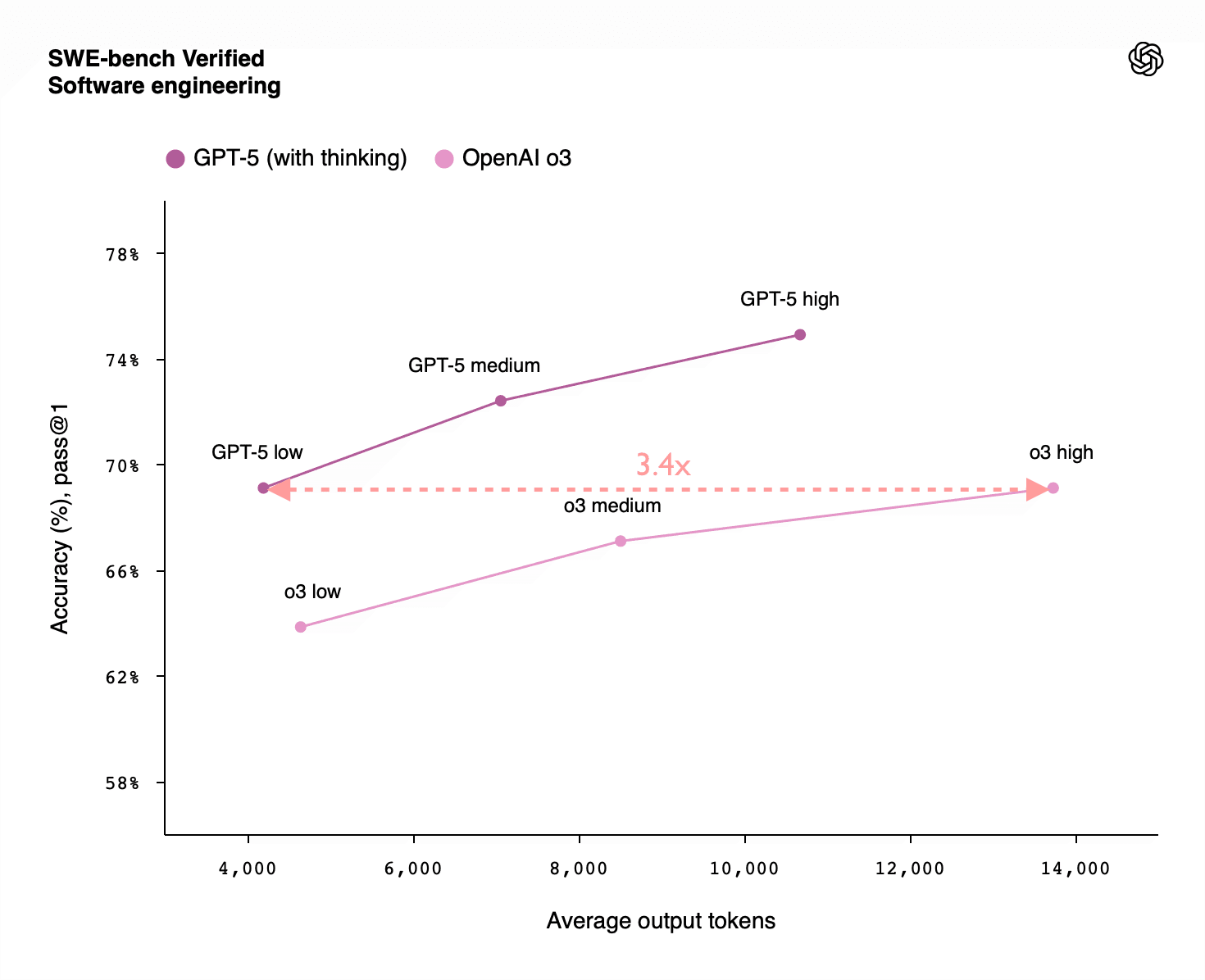
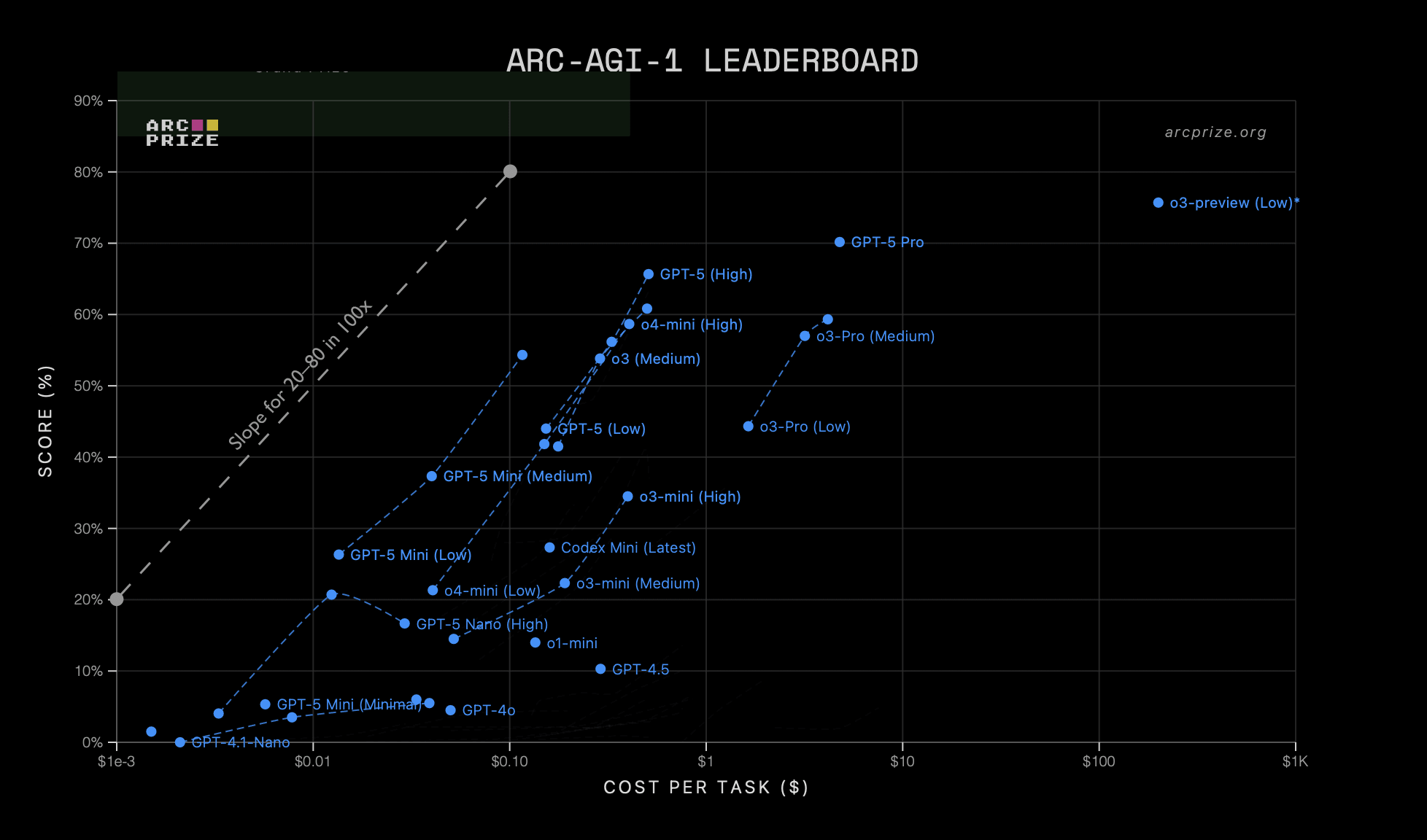
Summary: RL-training for LLMs scales surprisingly poorly. Most of its gains are from allowing LLMs to productively use longer chains of thought, allowing them to think longer about a problem. There is some improvement for a fixed length of answer, but not enough to drive AI progress. Given the scaling up of pre-training compute also stalled, we'll see less AI progress via compute scaling than you might have thought, and more of it will come from inference scaling (which has different effects on the world). That lengthens timelines and affects strategies for AI governance and safety.
The current era of improving AI capabilities using reinforcement learning (from verifiable rewards) involves two key types of scaling:
---
Outline:
(09:46) How do these compare to pre-training scaling?
(14:16) Conclusion
---
First published:
October 22nd, 2025
Source:
https://www.lesswrong.com/posts/xpj6KhDM9bJybdnEe/how-well-does-rl-scale
---
Narrated by TYPE III AUDIO.
---
…
continue reading
You can find the others on my site.
Summary: RL-training for LLMs scales surprisingly poorly. Most of its gains are from allowing LLMs to productively use longer chains of thought, allowing them to think longer about a problem. There is some improvement for a fixed length of answer, but not enough to drive AI progress. Given the scaling up of pre-training compute also stalled, we'll see less AI progress via compute scaling than you might have thought, and more of it will come from inference scaling (which has different effects on the world). That lengthens timelines and affects strategies for AI governance and safety.
The current era of improving AI capabilities using reinforcement learning (from verifiable rewards) involves two key types of scaling:
- Scaling the amount of compute used for RL during training
- Scaling [...]
---
Outline:
(09:46) How do these compare to pre-training scaling?
(14:16) Conclusion
---
First published:
October 22nd, 2025
Source:
https://www.lesswrong.com/posts/xpj6KhDM9bJybdnEe/how-well-does-rl-scale
---
Narrated by TYPE III AUDIO.
---
672 حلقات



