
))
Is finetuning GPT4o worth it? — with Alistair Pullen, Cosine (Genie)
Manage episode 435598066 series 3451473
المحتوى المقدم من swyx & Alessio. يتم تحميل جميع محتويات البودكاست بما في ذلك الحلقات والرسومات وأوصاف البودكاست وتقديمها مباشرة بواسطة swyx & Alessio أو شريك منصة البودكاست الخاص بهم. إذا كنت تعتقد أن شخصًا ما يستخدم عملك المحمي بحقوق الطبع والنشر دون إذنك، فيمكنك اتباع العملية الموضحة هنا https://ar.player.fm/legal.
Betteridge's law says no: with seemingly infinite flavors of RAG, and >2million token context + prompt caching from Anthropic/Deepmind/Deepseek, it's reasonable to believe that "in context learning is all you need".
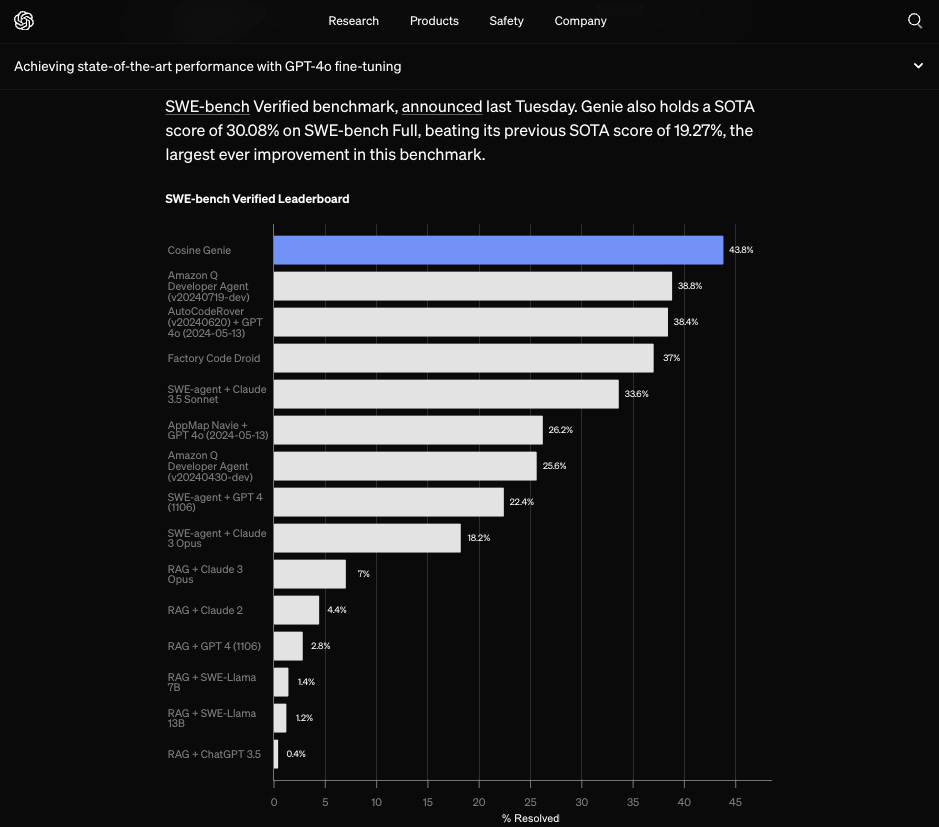
But then there’s Cosine Genie, the first to make a huge bet using OpenAI’s new GPT4o fine-tuning for code at the largest scale it has ever been used externally; resulting in what is now the #1 coding agent in the world according to SWE-Bench Full, Lite, and Verified:
SWE-Bench has been the most successful agent benchmark of the year, receiving honors at ICLR (our interview here) and recently being verified by OpenAI. Cognition (Devin) was valued at $2b after reaching 14% on it. So it is very, very big news when a new agent appears to beat all other solutions, by a lot:

While this number is self reported1, it seems to be corroborated by OpenAI, who also award it clear highest marks on SWE-Bench verified:
The secret is GPT-4o finetuning on billions of tokens of synthetic data.
Finetuning: As OpenAI says:
Genie is powered by a fine-tuned GPT-4o model trained on examples of real software engineers at work, enabling the model to learn to respond in a specific way. The model was also trained to be able to output in specific formats, such as patches that could be committed easily to codebases.
Due to the scale of Cosine’s finetuning, OpenAI worked closely with them to figure out the size of the LoRA:
“They have to decide how big your LoRA adapter is going to be… because if you had a really sparse, large adapter, you’re not going to get any signal in that at all. So they have to dynamically size these things.”
Synthetic data: we need to finetune on the process of making code work instead of only training on working code.
“…we synthetically generated runtime errors. Where we would intentionally mess with the AST to make stuff not work, or index out of bounds, or refer to a variable that doesn't exist, or errors that the foundational models just make sometimes that you can't really avoid, you can't expect it to be perfect.”
Genie also has a 4 stage workflow with the standard LLM OS tooling stack that lets it solve problems iteratively:
Full Video Pod
like and subscribe etc!
Show Notes
Cosine Genie launch, technical report
Timestamps
[00:00:00] Suno Intro
[00:05:01] Alistair and Cosine intro
[00:16:34] GPT4o finetuning
[00:20:18] Genie Data Mix
[00:23:09] Customizing for Customers
[00:25:37] Genie Workflow
[00:27:41] Code Retrieval
[00:35:20] Planning
[00:42:29] Language Mix
[00:43:46] Running Code
[00:46:19] Finetuning with OpenAI
[00:49:32] Synthetic Code Data
[00:51:54] SynData in Llama 3
[00:52:33] SWE-Bench Submission Process
[00:58:20] Future Plans
[00:59:36] Ecosystem Trends
[01:00:55] Founder Lessons
[01:01:58] CTA: Hiring & Customers
Descript Transcript
[00:01:52] AI Charlie: Welcome back. This is Charlie, your AI cohost. As AI engineers, we have a special focus on coding agents, fine tuning, and synthetic data. And this week, it all comes together with the launch of Cosign's Genie, which reached 50 percent on SWE Bench Lite, 30 percent on the full SWE Bench, and 44 percent on OpenAI's new SWE Bench Verified.
[00:02:17] All state of the art results by the widest ever margin recorded compared to former leaders Amazon Q and US Autocode Rover. And Factory Code Droid. As a reminder, Cognition Devon went viral with a 14 percent score just five months ago. Cosign did this by working closely with OpenAI to fine tune GPT 4. 0, now generally available to you and me, on billions of tokens of code, much of which was synthetically generated.
[00:02:47] Alistair Pullen: Hi, I'm Ali. Co founder and CEO of Cosign, a human reasoning lab. And I'd like to show you Genie, our state of the art, fully autonomous software engineering colleague. Genie has the highest score on SWBench in the world. And the way we achieved this was by taking a completely different approach. We believe that if you want a model to behave like a software engineer, it has to be shown how a human software engineer works.
[00:03:15] We've designed new techniques to derive human reasoning from real examples of software engineers doing their jobs. Our data represents perfect information lineage, incremental knowledge discovery, and step by step decision making. Representing everything a human engineer does logically. By actually training Genie on this unique dataset, rather than simply prompting base models, which is what everyone else is doing, we've seen that we're no longer simply generating random code until some works.
[00:03:46] It's tackling problems like
[00:03:48] AI Charlie: a human. Alistair Pullen is CEO and co founder of Kozen, and we managed to snag him on a brief trip stateside for a special conversation on building the world's current number one coding agent. Watch out and take care.
[00:04:07] Alessio: Hey everyone, welcome to the Latent Space Podcast. This is Alessio, partner and CTO of Resonance at Decibel Partners, and I'm joined by my co host Swyx, founder of Small. ai.
[00:04:16] swyx: Hey, and today we're back in the studio. In person, after about three to four months in visa jail and travels and all other fun stuff that we talked about in the previous episode.
[00:04:27] But today we have a special guest, Ali Pullen from Cosign. Welcome. Hi, thanks for having me. We're very lucky to have you because you're on a two day trip to San Francisco. Yeah, I wouldn't recommend it. I would not
[00:04:38] Alistair Pullen: recommend it. Don't fly from London to San Francisco for two days.
[00:04:40] swyx: And you launched Genie on a plane.
[00:04:42] On plain Wi Fi, um, claiming state of the art in SuiteBench, which we're all going to talk about. I'm excited to dive into your whole journey, because it has been a journey. I've been lucky to be a small angel in part of that journey. And it's exciting to see that you're launching to such acclaim and, you know, such results.
[00:05:01] Alistair and Cosine intro
[00:05:01] swyx: Um, so I'll go over your brief background, and then you can sort of fill in the blanks on what else people should know about you. You did your bachelor's in computer science at Exeter.
[00:05:10] Speaker 6: Yep.
[00:05:10] swyx: And then you worked at a startup that got acquired into GoPuff and round about 2022, you started working on a stealth startup that became a YC startup.
[00:05:19] What's that? Yeah. So
[00:05:21] Alistair Pullen: basically when I left university, I, I met my now co founder, Sam. At the time we were both mobile devs. He was an Android developer. iOS developer. And whilst at university, we built this sort of small consultancy, sort of, we'd um, be approached to build projects for people and we would just take them up and start with, they were student projects.
[00:05:41] They weren't, they weren't anything crazy or anything big. We started with those and over time we started doing larger and larger projects, more interesting things. And then actually, when we left university, we just kept doing that. We didn't really get jobs, traditional jobs. It was also like in the middle of COVID, middle of lockdown.
[00:05:57] So we were like, this is a pretty good gig. We'll just keep like writing code in our bedrooms. And yeah, that's it. We did that for a while. And then a friend of ours that we went to Exeter with started a YC startup during COVID. And it was one of these fast grocery delivery companies. At the time I was living in the deepest, darkest countryside in England, where fast grocery companies are still not a thing.
[00:06:20] So he, he sort of pitched me this idea and was like, listen, like I need an iOS dev, do you fancy coming along? And I thought, absolutely. It was a chance to get out of my parents house, chance to move to London, you know, do interesting things. And at the time, truthfully, I had no idea what YC was. I had no idea.
[00:06:34] I wasn't in the startup space. I knew I liked coding and building apps and stuff, but I'd never, never really done anything in that area. So I said, yes, absolutely. I moved to London just sort of as COVID was ending and yeah, worked at what was fancy for about a year and a half. Then we brought Sam along as well.
[00:06:52] So we, Sam and I, were the two engineers at Fancy for basically its entire life, and we built literally everything. So like the, the front, the client mobile apps, the, the backends, the internal like stock management system, the driver routing, algorithms, all those things. Literally like everything. It was my first.
[00:07:12] You know, both of us were super inexperienced. We didn't have, like, proper engineering experience. There were definitely decisions we'd do differently now. We'd definitely buy a lot of stuff off the shelf, stuff like that. But it was the initial dip of the toe into, like, the world of startups, and we were both, like, hooked immediately.
[00:07:26] We were like, this is so cool. This sounds so much better than all our friends who were, like, consultants and doing, like, normal jobs, right? We did that, and it ran its course, and after, I want to say, 18 months or so, GoPuff came and acquired us. And there was obviously a transitionary period, an integration period, like with all acquisitions, and we did that, and as soon as we'd vested what we wanted to vest, and as soon as we thought, okay, this chapter is sort of done, uh, in about 2022, We left and we knew that we wanted to go alone and try something like we'd had this taste.
[00:07:54] Now we knew we'd seen how a like a YC startup was managed like up close and we knew that we wanted to do something similar ourselves. We had no idea what it was at the time. We just knew we wanted to do something. So we, we tried a small, um, some small projects in various different areas, but then GPT 3.
[00:08:12] He'd seen it on Reddit and I'm his source of all knowledge. Yeah, Sam loves Reddit. I'd actually heard of GPT 2. And obviously had like loosely followed what OpenAI had done with, what was the game they trained a model to play? Dota. Was it Dota? Yeah. So I'd followed that and, I knew loosely what GPT 2 was, I knew what BERT was, so I was like, Okay, this GPT 3 thing sounds interesting.
[00:08:35] And he just mentioned it to me on a walk. And I then went home and, like, googled GPT was the playground. And the model was DaVinci 2 at the time. And it was just the old school playground, completions, nothing crazy, no chat, no nothing. I miss completions though. Yeah. Oh, completion. Honestly, I had this conversation in open hours office yesterday.
[00:08:54] I was like, I just went. I know. But yeah, so we, we, um, I started playing around with the, the playground and the first thing I ever wrote into it was like, hello world, and it gave me some sort of like, fairly generic response back. I was like, okay, that looks pretty cool. The next thing was. I looked through the docs, um, also they had a lot of example prompts because I had no idea.
[00:09:14] I didn't know if the, if you could put anything in, I didn't know if you had to structure in a certain way or whatever, and I, and I saw that it could start writing like tables and JSON and stuff like that. So I was like, okay, can you write me something in JSON? And it did. And I was like, Oh, wow, this is, this is pretty cool.
[00:09:28] Um, can it, can it just write arbitrary JSON for me? And, um, immediately as soon as I realized that my mind was racing and I like got Sam in and we just started messing around in the playground, like fairly innocently to start with. And then, of course, both being mobile devs and also seeing, at that point, we learned about what the Codex model was.
[00:09:48] It was like, this thing's trained to write code, sounds awesome. And Copilot was start, I think, I can't actually remember if Copilot had come out yet, it might have done. It's round about the same time as Codex. Round about the same time, yeah. And we were like, okay, as mobile devs, let's see what we can do.
[00:10:02] So the initial thing was like, okay, let's see if we can get this AI to build us a mobile app from scratch. We eventually built the world's most flimsy system, which was back in the day with like 4, 000 token context windows, like chaining prompts, trying to keep as much context from one to the other, all these different things, where basically, Essentially, you'd put an app idea in a box, and then we'd do, like, very high level stuff, figuring out what the stack should be, figuring out what the frontend should be written in, backend should be written in, all these different things, and then we'd go through, like, for each thing, more and more levels of detail, until the point that you're You actually got Codex to write the code for each thing.
[00:10:41] And we didn't do any templating or anything. We were like, no, we're going to write all the code from scratch every time, which is basically why it barely worked. But there were like occasions where you could put in something and it would build something that did actually run. The backend would run, the database would work.
[00:10:54] And we were like, Oh my God, this is insane. This is so cool. And that's what we showed to our co founder Yang. I met my co founder Yang through, through fancy because his wife was their first employee. And, um, we showed him and he was like, You've discovered fire. What is this? This is insane. He has a lot more startup experience.
[00:11:12] Historically, he's had a few exits in the past and has been through all different industries. He's like our dad. He's a bit older. He hates me saying that. He's your COO now? He's our COO. Yeah. And, uh, we showed him and he was like, this is absolutely amazing. Let's just do something. Cause he, he, at the time, um, was just about to have a child, so he didn't have anything going on either.
[00:11:29] So we, we applied to YC, got an interview. The interview was. As most YC interviews are short, curt, and pretty brutal. They told us they hated the idea. They didn't think it would work. And that's when we started brainstorming. It was almost like the interview was like an office hours kind of thing. And we were like, okay, given what you know about the space now and how to build things with these LLMs, like what can you bring out of what you've learned in building that thing into Something that might be a bit more useful to people on the daily, and also YC obviously likes B2B startups a little bit more, at least at the time they did, back then.
[00:12:01] So we were like, okay, maybe we could build something that helps you with existing codebases, like can sort of automate development stuff with existing codebases, not knowing at all what that would look like, or how you would build it, or any of these things. And They were like, yeah, that sounds interesting.
[00:12:15] You should probably go ahead and do that. You're in, you've got two weeks to build us an MVP. And we were like, okay, okay. We did our best. The MVP was absolutely horrendous. It was a CLI tool. It sucked. And, um, at the time we were like, we, we don't even know. How to build what we want to build. And we didn't really know what we wanted to build, to be honest.
[00:12:33] Like, we knew we wanted to try to help automate dev work, but back then we just didn't know enough about how LLM apps were built, the intricacies and all those things. And also, like, the LLMs themselves, like 4, 000 tokens, you're not going very far, they're extremely expensive. So we ended up building a, uh, a code based retrieval tool, originally.
[00:12:51] Our thought process originally was, we want to build something that can do our jobs for us. That is like the gold star, we know that. We've seen like there are glimpses of it happening with our initial demo that we did. But we don't see the path of how to do that at the moment. Like the tech just wasn't there.
[00:13:05] So we were like, well, there are going to be some things that you need to build this when the tech does catch up. So retrieval being one of the most important things, like the model is going to have to build like pull code out of a code base somehow. So we were like, well, let's just build the tooling around it.
[00:13:17] And eventually when the tech comes, then we'll be able to just like plug it into our, our tooling and then it should work basically. And to be fair, that's basically what we've done. And that's basically what's happened, which is very fortunate. But in the meantime, whilst we were waiting for everything to sort of become available, we built this code base retrieval tool.
[00:13:34] That was the first thing we ever launched when we were in YC like that, and it didn't work. It was really frustrating for us because it was just me and Sam like working like all hours trying to get this thing to work. It was quite a big task in of itself, trying to get like a good semantic search engine working that could run locally on your machine.
[00:13:51] We were trying to avoid sending code to the cloud as much as possible. And then for very large codebases, you're like, you know, millions of lines of code. You're trying to do some sort of like local HNSW thing that runs inside your VS Code instance that like eats all your RAM as you've seen in the past.
[00:14:05] All those different things. Yep. Yeah.
[00:14:07] swyx: My first call with
[00:14:07] Alistair Pullen: you, I had trouble. You were like, yeah, it sucks, man. I know, I know. I know it sucks. I'm sorry. I'm sorry. But building all that stuff was essentially the first six to eight months of what at the time was built. Which, by the way, build it. Build it. Yeah, it was a terrible, terrible name.
[00:14:25] It was the worst,
[00:14:27] swyx: like, part of trying to think about whether I would invest is whether or not people could pronounce it.
[00:14:32] Alistair Pullen: No, when we, so when we went on our first ever YC, like, retreat, No one got the name right. They were like, build, build, well, um, and then we actually changed the names, cosign, like, although some people would spell it as in like, as if you're cosigning for an apartment or something like that's like, can't win.
[00:14:49] Yeah. That was what built was back then. But the ambition, and I did a talk on this back in the end of 2022, the ambition to like build something that essentially automated our jobs was still very much like core to what we were doing. But for a very long time, it was just never apparent to us. Like. How would you go about doing these things?
[00:15:06] Even when, like, you had 3. suddenly felt huge, because you've gone from 4 to 16, but even then 16k is like, a lot of Python files are longer than 16k. So you can't, you know, before you even start doing a completion, even then we were like, eh, Yeah, it looks like we're still waiting. And then, like, towards the end of last year, you then start, you see 32k.
[00:15:28] 32k was really smart. It was really expensive, but also, like, you could fit a decent amount of stuff in it. 32k felt enormous. And then, finally, 128k came along, and we were like, right, this is, like, this is what we can actually deal with. Because, fundamentally, to build a product like this, you need to get as much information in front of the model as possible, and make sure that everything it ever writes in output can be read.
[00:15:49] traced back to something in the context window, so it's not hallucinating it. As soon as that model existed, I was like, okay, I know that this is now going to be feasible in some way. We'd done early sort of dev work on Genie using 3. 5 16k. And that was a very, very like crude way of proving that this loop that we were after and the way we were generating the data actually had signal and worked and could do something.
[00:16:16] But the model itself was not useful because you couldn't ever fit enough information into it for it to be able to do the task competently and also the base intelligence of the model. I mean, 3. 5, anyone who's used 3. 5 knows the base intelligence of the model is. is lacking, especially when you're asking it to like do software engineering, this is quite quite involved.
[00:16:34] GPT4o finetuning
[00:16:34] Alistair Pullen: So, we saw the 128k context model and um, at that point we'd been in touch with OpenAI about our ambitions and like how we wanted to build it. We essentially are, I just took a punt, I was like, I'm just going to ask to see, can we like train this thing? Because at the time Fortobo had just come out and back then there was still a decent amount of lag time between like OpenAI releasing a model and then allowing you to fine tune it in some way.
[00:16:59] They've gotten much better about that recently, like 4. 0 fine tuning came out either, I think, a day, 4. 0 mini fine tuning came out like a day after the model did. And I know that's something they're definitely like, optimising for super heavily inside, which is great to see.
[00:17:11] swyx: Which is a little bit, you know, for a year or so, YC companies had like a direct Slack channel to open AI.
[00:17:17] We still do. Yeah. Yeah. So, it's a little bit of a diminishing of the YC advantage there. Yeah. If they're releasing this fine tuning
[00:17:23] Alistair Pullen: ability like a day after. Yeah, no, no, absolutely. But like. You can't build a startup otherwise. The advantage is obviously nice and it makes you feel fuzzy inside. But like, at the end of the day, it's not that that's going to make you win.
[00:17:34] But yeah, no, so like we'd spoken to Shamul there, Devrel guy, I'm sure you know him. I think he's head of solutions or something. In their applied team, yeah, we'd been talking to him from the very beginning when we got into YC, and he's been absolutely fantastic throughout. I basically had pitched him this idea back when we were doing it on 3.
[00:17:53] 5, 16k, and I was like, this is my, this is my crazy thesis. I want to see if this can work. And as soon as like that 128k model came out, I started like laying the groundwork. I was like, I know this definitely isn't possible because he released it like yesterday, but know that I want it. And in the interim, like, GPT 4, like, 8K fine tuning came out.
[00:18:11] We tried that, it's obviously even fewer tokens, but the intelligence helped. And I was like, if we can marry the intelligence and the context window length, then we're going to have something special. And eventually, we were able to get on the Experimental Access Program, and we got access to 4Turbo fine tuning.
[00:18:25] As soon as we did that, because in the entire run up to that we built the data pipeline, we already had all that set up, so we were like, right, we have the data, now we have the model, let's put it through and iterate, essentially, and that's, that's where, like, Genie as we know it today, really was born. I won't pretend like the first version of Gene that we trained was good.
[00:18:45] It was a disaster. That's where you realize all the implicit biases in your data set. And you realize that, oh, actually this decision you made that was fairly arbitrary was the wrong one. You have to do it a different way. Other subtle things like, you know, how you write Git diffs in using LLMs and how you can best optimize that to make sure they actually apply and work and loads of different little edge cases.
[00:19:03] But as soon as we had access to the underlying tool, we were like, we can actually do this. And I was I breathed a sigh of relief because I didn't know it was like, it wasn't a done deal, but I knew that we could build something useful. I mean, I knew that we could build something that would be measurably good on whatever eval at the time that you wanted to use.
[00:19:23] Like at the time, back then, we weren't actually that familiar with Swift. But once Devin came out and they announced the SBBench core, I like, that's when my life took a turn. Challenge accepted. Yeah, challenge accepted. And that's where like, yes, that's where my friendships have gone. My sleep has gone. My weight.
[00:19:40] Everything got into SweeBench and yeah, we, we, it was actually a very useful tool in building GeniX beforehand. It was like, yes, vibe check this thing and see if it's useful. And then all of a sudden you have a, an actual measure to, to see like, couldn't it do software engineering? Not, not the best measure, obviously, but like it's a, it's the best that we've got now.
[00:19:57] We, we just iterated and built and eventually we got it to the point where it is now. And a little bit beyond since we actually Like, we actually got that score a couple of weeks ago, and yeah, it's been a hell of a journey from the beginning all the way now. That was a very rambling answer to your question about how we got here, but that's essentially the potted answer of how we got here.
[00:20:16] Got the full
[00:20:16] swyx: origin story
[00:20:17] Alessio: out. Yeah, no, totally.
[00:20:18] Genie Data Mix
[00:20:18] Alessio: You mentioned bias in the data and some of these things. In your announcement video, you called Genie the worst verse AI software engineering colleague. And you kind of highlighted how the data needed to train it needs to show how a human engineer works. I think maybe you're contrasting that to just putting code in it.
[00:20:37] There's kind of like a lot more than code that goes into software engineering. How do you think about the data mixture, you know, and like, uh, there's this kind of known truth that code makes models better when you put in the pre training data, but since we put so much in the pre training data, what else do you add when you turn to Genium?
[00:20:54] Alistair Pullen: Yeah, I think, well, I think that sort of boils down fundamentally to the difference between a model writing code and a model doing software engineering, because the software engineering sort of discipline goes wider, because if you look at something like a PR, that is obviously a Artifact of some thought and some work that has happened and has eventually been squashed into, you know, some diffs, right?
[00:21:17] What the, very crudely, what the pre trained models are reading is they're reading those final diffs and they're emulating that and they're being able to output it, right? But of course, it's a super lossy thing, a PR. You have no idea why or how, for the most part, unless there are some comments, which, you know, anyone who's worked in a company realizes PR reviews can be a bit dodgy at times, but you see that you lose so much information at the end, and that's perfectly fine, because PRs aren't designed to be something that perfectly preserves everything that happened, but What we realized was if you want something that's a software engineer, and very crudely, we started with like something that can do PRs for you, essentially, you need to be able to figure out why those things happened.
[00:21:58] Otherwise, you're just going to rely, you essentially just have a code writing model, you have something that's good at human eval, but But, but not very good at Sweet Eng. Essentially that realization was, was part of the, the kernel of the idea of of, of the approach that we took to design the agent. That, that is genie the way that we decided we want to try to extract what happened in the past, like as forensically as possible, has been and is currently like one of the, the main things that we focus all our time on, because doing that as getting as much signal out as possible, doing that as well as possible is the biggest.
[00:22:31] thing that we've seen that determines how well we do on that benchmark at the end of the day. Once you've sorted things out, like output structure, how to get it consistently writing diffs and all the stuff that is sort of ancillary to the model actually figuring out how to solve a problem, the core bit of solving the problem is how did the human solve this problem and how can we best come up with how the human solved these problems.
[00:22:54] So all the effort went in on that. And the mix that we ended up with was, as you've probably seen in the technical report and so on, all of those different languages and different combinations of different task types, all of that has run through that pipeline, and we've extracted all that information out.
[00:23:09] Customizing for Customers
[00:23:09] Alessio: How does that differ when you work with customers that have private workflows? Like, do you think, is there usually a big delta between what you get in open source and maybe public data versus like Yeah,
[00:23:19] Alistair Pullen: yeah, yeah. When you scrape enough of it, most of open source is updating readmes and docs. It's hilarious, like we had to filter out so much of that stuff because when we first did the 16k model, like the amount of readme updating that went in, we did like no data cleaning, no real, like, we just sort of threw it in and saw what happened.
[00:23:38] And it was just like, It was really good at updating readme, it was really good at writing some comments, really good at, um, complaining in Git reviews, in PR reviews, rather, and it would, again, like, we didn't clean the data, so you'd, like, give it some feedback, and it would just, like, reply, and, like, it would just be quite insubordinate when it was getting back to you, like, no, I don't think you're right, and it would just sort of argue with you, so The process of doing all that was super interesting because we realized from the beginning, okay, there's a huge amount of work that needs to go into like cleaning this, getting it aligned with what we want the model to do to be able to get the model to be useful in some way.
[00:24:12] Alessio: I'm curious, like, how do you think about the customer willingness? To share all of this historical data, I've done a lot of developer tools investing in my career and getting access to the code base is always one of the hard things. Are people getting more cautious about sharing this information? In the past, it was maybe like, you know, you're using static analysis tool, like whatever else you need to plug into the code base, fine.
[00:24:35] Now you're building. A model based on it, like, uh, what's the discussion going into these companies? Are most people comfortable with, like, letting you see how to work and sharing everything?
[00:24:44] Alistair Pullen: It depends on the sector, mostly. We've actually seen, I'd say, people becoming more amenable to the idea over time, actually, rather than more skeptical, because I think they can see the, the upside.
[00:24:55] If this thing could be, Does what they say it does, it's going to be more help to us than it is a risk to our infosec. Um, and of course, like, companies building in this space, we're all going to end up, you know, complying with the same rules, and there are going to be new rules that come out to make sure that we're looking at your code, that everything is safe, and so on.
[00:25:12] So from what we've seen so far, we've spoken to some very large companies that you've definitely heard of and all of them obviously have stipulations and many of them want it to be sandbox to start with and all the like very obvious things that I, you know, I would say as well, but they're all super keen to have a go and see because like, despite all those things, if we can genuinely Make them go faster, allow them to build more in a given time period and stuff.
[00:25:35] It's super worth it to them.
[00:25:37] Genie Workflow
[00:25:37] swyx: Okay, I'm going to dive in a little bit on the process that you have created. You showed the demo on your video, and by the time that we release this, you should be taking people off the waitlist and launching people so people can see this themselves. There's four main Parts of the workflow, which is finding files, planning action, writing code and running tests.
[00:25:58] And controversially, you have set yourself apart from the Devins of the world by saying that things like having access to a browser is not that important for you. Is that an accurate reading of
[00:26:09] Alistair Pullen: what you wrote? I don't remember saying that, but At least with what we've seen, the browser is helpful, but it's not as helpful as, like, ragging the correct files, if that makes sense.
[00:26:20] Like, it is still helpful, but obviously there are more fundamental things you have to get right before you get to, like, Oh yeah, you can read some docs, or you can read a stack overflow article, and stuff like that.
[00:26:30] swyx: Yeah, the phrase I was indexing on was, The other software tools are wrappers around foundational models with a few additional tools, such as a web browser or code interpreter.
[00:26:38] Alistair Pullen: Oh, I see. No, I mean, no, I'm, I'm not, I'm not, I'm not deri, I'm deriding the, the, the approach that, not the, not the tools. Yeah, exactly. So like, I would
[00:26:44] swyx: say in my standard model of what a code agent should look like, uh, Devon has been very influential, obviously. Yeah. Yeah. Because you could just add the docs of something.
[00:26:54] Mm-Hmm. . And like, you know, now I have, now when I'm installing a new library, I can just add docs. Yeah, yeah. Cursor also does this. Right. And then obviously having a code interpreter does help. I guess you have that in the form
[00:27:03] Alistair Pullen: of running tests. I mean, uh, the Genie has both of those tools available to it as well.
[00:27:08] So, yeah, yeah, yeah. So, we have a tool where you can, like, put in URLs and it will just read the URLs. And you can also use this Perplexities API under the hood as well to be able to actually ask questions if it wants to. Okay. So, no, we use both of those tools as well. Like, those tools are Super important and super key.
[00:27:24] I think obviously the most important tools to these agents are like being able to retrieve code from a code base, being able to read Stack Overflow articles and what have you and just be able to essentially be able to Google like we do is definitely super useful.
[00:27:38] swyx: Yeah, I thought maybe we could just kind of dive into each of those actions.
[00:27:41] Code Retrieval
[00:27:41] swyx: Code retrieval, one of the core indexer that Yes. You've worked on, uh, even as, as built, what makes it hard, what approach you thought would work, didn't work,
[00:27:52] Alistair Pullen: anything like that. It's funny, I had a similar conversation to this when I was chatting to the guys from OpenAI yesterday. The thing is that searching for code, specifically semantically, at least to start with, I mean like keyword search and stuff like that is a, is a solved problem.
[00:28:06] It's been around for ages, but at least being able to, the phrase we always used back in the day was searching for what code does rather than what code is. Like searching for functionality is really hard. Really hard. The way that we approached that problem was that obviously like a very basic and easy approach is right.
[00:28:26] Let's just embed the code base. We'll chunk it up in some arbitrary way, maybe using an AST, maybe using number of lines, maybe using whatever, like some overlapping, just chunk it up and embed it. And once you've done that, I will write a query saying, like, find me some authentication code or something, embed it, and then do the cosine similarity and get the top of K, right?
[00:28:43] That doesn't work. And I wish it did work, don't get me wrong. It doesn't work well at all, because fundamentally, if you think about, like, semantically, how code looks is very different to how English looks, and there's, like, not a huge amount of signal that's carried between the two. So what we ended up, the first approach we took, and that kind of did well enough for a long time, was Okay, let's train a model to be able to take in English code queries and then produce a hypothetical code snippet that might look like the answer, embed that, and then do the code similarity.
[00:29:18] And that process, although very simple, gets you so much more performance out of the retrieval accuracy. And that was kind of like the start of our of our engine, as we called it, which is essentially like the aggregation of all these different heuristics, like semantic, keyword, LSP, and so on. And then we essentially had like a model that would, given an input, choose which ones it thought were most appropriate, given the type of requests you had.
[00:29:45] So the whole code search thing was a really hard problem. And actually what we ended up doing with Genie is we, um, let The model through self play figure out how to retrieve code. So actually we don't use our engine for Genie. So instead of like a request coming in and then like say GPT 4 with some JSON output being like, Well, I think here we should use a keyword with these inputs and then we should use semantic.
[00:30:09] And then we should like pick these results. It's actually like, A question comes in and Genie has self played in its training data to be able to be like, okay, this is how I'm going to approach finding this information. Much more akin to how a developer would do it. Because if I was like, Shawn, go into this new code base you've never seen before.
[00:30:26] And find me the code that does this. You're gonna probably, you might do some keywords, you're gonna look over the file system, you're gonna try to figure out from the directories and the file names where it might be, you're gonna like jump in one, and then once you're in there, you're probably gonna be doing the, you know, go to definition stuff to like jump from file to file and try to use the graph to like get closer and closer.
[00:30:46] And that is exactly what Genie does. Starts on the file system, looks at the file system, picks some candidate files, is this what I'm looking for, yes or no, and If there's something that's interesting, like an import or something, it can, it can command click on that thing, go to definition, go to references, and so on.
[00:31:00] And it can traverse the codebase that way.
[00:31:02] swyx: Are you using the VS Code, uh, LSP, or? No,
[00:31:05] Alistair Pullen: that's not, we're not like, we're not doing this in VS Code, we're just using the language servers running. But, we really wanted to try to mimic the way we do it as best as possible. And we did that during the self play process when we were generating the dataset, so.
[00:31:18] Although we did all that work originally, and although, like, Genie still has access to these tools, so it can do keyword searches, and it can do, you know, basic semantic searches, and it can use the graph, it uses them through this process and figures out, okay, I've learned from data how to find stuff in codebases, and I think in our technical report, I can't remember the exact number, but I think it was around 65 or 66 percent retrieval accuracy overall, Measured on, we know what lines we need for these tasks to find, for the task to actually be able to be completed, And we found about 66 percent of all those lines, which is one of the biggest areas of free performance that we can get a hold of, because When we were building Genie, truthfully, like, a lot more focus went on assuming you found the right information, you've been able to reproduce the issue, assuming that's true, how do you then go about solving it?
[00:32:08] And the bulk of the work we did was on the solving. But when you go higher up the funnel, obviously, like, the funnel looks like, have you found everything you need for the task? Are you able to reproduce the problem that's seen in the issue? Are you then able to solve it? And the funnel gets narrower as you go down.
[00:32:22] And at the top of the funnel, of course, is rank. So I'm actually quite happy with that score. I think it's still pretty impressive considering the size of some of the codebases we're doing, we're using for this. But as soon as that, if that number becomes 80, think how many more tasks we get right. That's one of the key areas we're going to focus on when we continue working on Genie.
[00:32:37] It'd be interesting to break out a benchmark just for that.
[00:32:41] swyx: Yeah, I mean, it's super easy. Because I don't know what state of the art is.
[00:32:43] Alistair Pullen: Yeah, I mean, like, for a, um, it's super easy because, like, for a given PR, you know what lines were edited. Oh, okay. Yeah, you know what lines were
[00:32:50] swyx: you can
[00:32:51] Alistair Pullen: source it from Cbench, actually.
[00:32:52] Yeah, you can do it, you can do it super easily. And that's how we got that figure out at the other end. Um, for us being able to see it against, um, our historic models were super useful. So we could see if we were, you know, actually helping ourselves or not. And initially, one of the biggest performance gains that we saw when we were work, when we did work on the RAG a bit was giving it the ability to use the LSP to like go to definition and really try to get it to emulate how we do that, because I'm sure when you go into an editor with that, where like the LSP is not working or whatever, you suddenly feel really like disarmed and naked.
[00:33:20] You're like, Oh my god, I didn't realize how much I actually used this to get about rather than just find stuff. So we really tried to get it to do that and that gave us a big jump in performance. So we went from like 54 percent up to like the 60s, but just by adding, focusing on that.
[00:33:34] swyx: One weird trick. Yes.
[00:33:37] I'll briefly comment here. So this is the standard approach I would say most, uh, code tooling startups are pursuing. The one company that's not doing this is magic. dev. So would you do things differently if you have a 10 million
[00:33:51] Alistair Pullen: token context window? If I had a 10 million context window and hundreds of millions of dollars, I wouldn't have gone and built, uh, it's an LTM, it's not a transformer, right, that they're using, right?
[00:34:03] If I'm not mistaken, I believe it's not a transformer. Yeah, Eric's going to come on at some point. Listen, they obviously know a lot more about their product than I do. I don't know a great deal about how magic works. I don't think he knows anything yet. I'm not going to speculate. Would I do it the same way as them?
[00:34:17] I like the way we've done it because fundamentally like we focus on the Active software engineering and what that looks like and showing models how to do that. Fundamentally, the underlying model that we use is kind of null to us, like, so long as it's the best one, I don't mind. And the context windows, we've already seen, like, you can get transformers to have, like, million, one and a half million token context windows.
[00:34:43] And that works perfectly well, so like, as soon as you can fine tune Gemini 1. 5, then you best be sure that Genie will run on Gemini 1. 5, and like, we'll probably get very good performance out of that. I like our approach because we can be super agile and be like, Oh, well, Anthropic have just released whatever, uh, you know, and it might have half a million tokens and it might be really smart.
[00:35:01] And I can just immediately take my JSONL file and just dump it in there and suddenly Genie works on there and it can do all the new things. Does
[00:35:07] swyx: Anthropic have the same fine tuning support as OpenAI? I
[00:35:11] Alistair Pullen: actually haven't heard any, anyone do it because they're working on it. They are partner, they're partnered with AWS and it's gonna be in Bedrock.
[00:35:16] Okay. As far as, as far as I know, I think I'm, I think, I think that's true. Um, cool. Yeah.
[00:35:20] Planning
[00:35:20] swyx: We have to keep moving on to, uh, the other segments. Sure. Uh, planning the second piece of your four step grand master plan, that is the frontier right now. You know, a lot of people are talking about strawberry Q Star, whatever that is.
[00:35:32] Monte Carlo Tree Search. Is current state of the art planning good enough? What prompts have worked? I don't even know what questions to ask. Like, what is the state of planning?
[00:35:41] Alistair Pullen: I think it's fairly obvious that with the foundational models, like, you can ask them to think by step by step and ask them to plan and stuff, but that isn't enough, because if you look at how those models score on these benchmarks, then they're not even close to state of the art.
[00:35:52] Which ones are
[00:35:52] swyx: you referencing? Benchmarks? So, like,
[00:35:53] Alistair Pullen: just, uh, like, SweetBench and so on, right? And, like, even the things that get really good scores on human evalor agents as well, because they have these loops, right? Yeah. Obviously these things can reason, quote unquote, but the reasoning is the model, like, it's constrained by the model as intelligence, I'd say, very crudely.
[00:36:10] And what we essentially wanted to do was we still thought that, obviously, reasoning is super important, we need it to get the performance we have. But we wanted the reasoning to emulate how we think about problems when we're solving them as opposed to how a model thinks about a problem when we're solving it.
[00:36:23] And that was, that's obviously part of, like, the derivation pipeline that we have when we, when we, when we Design our data, but the reasoning that the models do right now, and who knows what Q star, whatever ends up being called looks like, but certainly what I'm excited on a small tangent to that, like, what I'm really excited about is when models like that come out, obviously, the signal in my data, when I regenerate, it goes up.
[00:36:44] And then I can then train that model. It's already better at reasoning with it. improved reasoning data and just like I can keep bootstrapping and keep leapfrogging every single time. And that is like super exciting to me because I don't, I welcome like new models so much because immediately it just floats me up without having to do much work, which is always nice.
[00:37:02] But at the state of reasoning generally, I don't see it going away anytime soon. I mean, that's like an autoregressive model doesn't think per se. And in the absence of having any thought Maybe, uh, an energy based model or something like that. Maybe that's what QSTAR is. Who knows? Some sort of, like, high level, abstract space where thought happens before tokens get produced.
[00:37:22] In the absence of that for the moment, I think it's all we have and it's going to have to be the way it works. For what happens in the future, we'll have to see, but I think certainly it's never going to hinder performance to do it. And certainly, the reasoning that we see Genie do, when you compare it to like, if you ask GPT 4 to break down step by step and approach for the same problem, at least just on a vibe check alone, looks far better.
[00:37:46] swyx: Two elements that I like, that I didn't see in your initial video, we'll see when, you know, this, um, Genie launches, is a planner chat, which is, I can modify the plan while it's executing, and then the other thing is playbooks, which is also from Devin, where, here's how I like to do a thing, and I'll use Markdown to, Specify how I do it.
[00:38:06] I'm just curious if, if like, you know,
[00:38:07] Alistair Pullen: those things help. Yeah, no, absolutely. We're a hundred percent. We want everything to be editable. Not least because it's really frustrating when it's not. Like if you're ever, if you're ever in a situation where like this is the one thing I just wish I could, and you'd be right if that one thing was right and you can't change it.
[00:38:21] So we're going to make everything as well, including the code it writes. Like you can, if it makes a small error in a patch, you can just change it yourself and let it continue and it will be fine. Yeah. So yeah, like those things are super important. We'll be doing those two.
[00:38:31] Alessio: I'm curious, once you get to writing code, is most of the job done?
[00:38:35] I feel like the models are so good at writing code when they're like, And small chunks that are like very well instructed. What's kind of the drop off in the funnel? Like once you get to like, you got the right files and you got the right plan. That's a great question
[00:38:47] Alistair Pullen: because by the time this is out, there'll be another blog, there'll be another blog post, which contains all the information, all the learnings that I delivered to OpenAI's fine tuning team when we finally got the score.
[00:38:59] Oh, that's good. Um, go for it. It's already up. And, um, yeah, yeah. I don't have it on my phone, but basically I, um, broke down the log probs. I basically got the average log prob for a token at every token position in the context window. So imagine an x axis from 0 to 128k and then the average log prob for each index in there.
[00:39:19] As we discussed, like, The way genie works normally is, you know, at the beginning you do your RAG, and then you do your planning, and then you do your coding, and that sort of cycle continues. The certainty of code writing is so much more certain than every other aspect of genie's loop. So whatever's going on under the hood, the model is really comfortable with writing code.
[00:39:35] There is no doubt, and it's like in the token probabilities. One slightly different thing, I think, to how most of these models work is, At least for the most part, if you ask GPT4 in ChatGPT to edit some code for you, it's going to rewrite the entire snippet for you with the changes in place. We train Genie to write diffs and, you know, essentially patches, right?
[00:39:55] Because it's more token efficient and that is also fundamentally We don't write patches as humans, but it's like, the result of what we do is a patch, right? When Genie writes code, I don't know how much it's leaning on the pre training, like, code writing corpus, because obviously it's just read code files there.
[00:40:14] It's obviously probably read a lot of patches, but I would wager it's probably read more code files than it has patches. So it's probably leaning on a different part of its brain, is my speculation. I have no proof for this. So I think the discipline of writing code is slightly different, but certainly is its most comfortable state when it's writing code.
[00:40:29] So once you get to that point, so long as you're not too deep into the context window, another thing that I'll bring up in that blog post is, um, Performance of Genie over the length of the context window degrades fairly linearly. So actually, I actually broke it down by probability of solving a SWE bench issue, given the number of tokens of the context window.
[00:40:49] It's 60k, it's basically 0. 5. So if you go over 60k in context length, you are more likely to fail than you are to succeed just based on the amount of tokens you have on the context window. And when I presented that to the fine tuning team at OpenAI, that was super interesting to them as well. And that is more of a foundational model attribute than it is an us attribute.
[00:41:10] However, the attention mechanism works in, in GPT 4, however, you know, they deal with the context window at that point is, you know, influencing how Genie is able to form, even though obviously all our, all our training data is perfect, right? So even if like stuff is being solved in 110, 000 tokens, sort of that area.
[00:41:28] The training data still shows it being solved there, but it's just in practice, the model is finding it much harder to solve stuff down that end of the context window.
[00:41:35] Alessio: That's the scale with the context, so for a 200k context size, is 100k tokens like the 0. 5? I don't know. Yeah, but I,
[00:41:43] Alistair Pullen: I, um, hope not. I hope you don't just take the context length and halve it and then say, oh, this is the usable context length.
[00:41:50] But what's been interesting is knowing that Actually really digging into the data, looking at the log probs, looking at how it performs over the entire window. It's influenced the short term improvements we've made to Genie since we did the, got that score. So we actually made some small optimizations to try to make sure As best we can without, like, overdoing it, trying to make sure that we can artificially make sure stuff sits within that sort of range, because we know that's our sort of battle zone.
[00:42:17] And if we go outside of that, we're starting to push the limits, we're more likely to fail. So just doing that sort of analysis has been super useful without actually messing with anything, um, like, more structural in getting more performance out of it.
[00:42:29] Language Mix
[00:42:29] Alessio: What about, um, different languages? So, in your technical report, the data makes sense.
[00:42:34] 21 percent JavaScript, 21 percent Python, 14 percent TypeScript, 14 percent TSX, um, Which is JavaScript, JavaScript.
[00:42:42] Alistair Pullen: Yeah,
[00:42:42] swyx: yeah, yeah. Yes,
[00:42:43] Alistair Pullen: yeah, yeah. It's like 49 percent JavaScript. That's true, although TypeScript is so much superior, but anyway.
[00:42:46] Alessio: Do you see, how good is it at just like generalizing? You know, if you're writing Rust or C or whatever else, it's quite different.
[00:42:55] Alistair Pullen: It's pretty good at generalizing. Um, obviously, though, I think there's 15 languages in that technical report, I think, that we've, that we've covered. The ones that we picked in the highest mix were, uh, the ones that, selfishly, we internally use the most, and also that are, I'd argue, some of the most popular ones.
[00:43:11] When we have more resource as a company, and, More time and, you know, once all the craziness that has just happened sort of dies down a bit, we are going to, you know, work on that mix. I'd love to see everything ideally be represented in a similar level as it is. If you, if you took GitHub as a data set, if you took like how are the languages broken down in terms of popularity, that would be my ideal data mix to start.
[00:43:34] It's just that it's not cheap. So, um, yeah, trying to have an equal amount of Ruby and Rust and all these different things is just, at our current state, is not really what we're looking for.
[00:43:46] Running Code
[00:43:46] Alessio: There's a lot of good Ruby in my GitHub profile. You can have it all. Well, okay, we'll just train on that. For running tests It sounds easy, but it isn't, especially when you're working in enterprise codebases that are kind of like very hard to spin up.
[00:43:58] Yes. How do you set that up? It's like, how do you make a model actually understand how to run a codebase, which is different than writing code for a codebase?
[00:44:07] Alistair Pullen: The model itself is not in charge of like setting up the codebase and running it. So Genie sits on top of GitHub, and if you have CI running GitHub, you have GitHub Actions and stuff like that, then Genie essentially makes a call out to that, runs your CI, sees the outputs and then like moves on.
[00:44:23] Making a model itself, set up a repo, wasn't scoped in what we wanted Genie to be able to do because for the most part, like, at least most enterprises have some sort of CI pipeline running and like a lot of, if you're doing some, even like, A lot of hobbyist software development has some sort of like basic CI running as well.
[00:44:40] And that was like the lowest hanging fruit approach that we took. So when, when Genie ships, like the way it will run its own code is it will basically run your CI and it will like take the, um, I'm not in charge of writing this. The rest of the team is, but I think it's the checks API on GitHub allows you to like grab that information and throw it in the context window.
[00:44:56] Alessio: What's the handoff like with the person? So, Jeannie, you give it a task, and then how long are you supposed to supervise it for? Or are you just waiting for, like, the checks to eventually run, and then you see how it goes? Like, uh, what does it feel like?
[00:45:11] Alistair Pullen: There are a couple of modes that it can run in, essentially.
[00:45:14] It can run in, like, fully headless autonomous modes, so say you assign it a ticket in linear or something. Then it won't ask you for anything. It will just go ahead and try. Or if you're in like the GUI on the website and you're using it, then you can give it a task and it, it might choose to ask you a clarifying question.
[00:45:30] So like if you ask it something super broad, it might just come back to you and say, what does that actually mean? Or can you point me in the right direction for this? Because like our decision internally was, it's going to piss people off way more if it just goes off and has, and makes a completely like.
[00:45:45] ruined attempt at it because it just like from day one got the wrong idea. So it can ask you for a lot of questions. And once it's going much like a regular PR, you can leave review comments, issue comments, all these different things. And it, because you know, he's been trained to be a software engineering colleague, responds in actually a better way than a real colleague, because it's less snarky and less high and mighty.
[00:46:08] And also the amount of filtering has to do for When you train a model to like be a software engineer, essentially, it's like you can just do anything. It's like, yeah, it looks good to me, bro.
[00:46:17] swyx: Let's
[00:46:17] Alistair Pullen: ship it.
[00:46:19] Finetuning with OpenAI
[00:46:19] swyx: I just wanted to dive in a little bit more on your experience with the fine tuning team. John Allard was publicly sort of very commentary supportive and, you know, was, was part of it.
[00:46:27] Like, what's it like working with them? I also picked up that you initially started to fine tune what was publicly available, the 16 to 32 K range. You got access to do more than that. Yeah. You've also trained on billions of tokens instead of the usual millions range. Just, like, take us through that fine tuning journey and any advice that you might have.
[00:46:47] Alistair Pullen: It's been so cool, and this will be public by the time this goes out, like, OpenAI themselves have said we are pushing the boundaries of what is possible with fine tuning. Like, we are right on the edge, and like, we are working, genuinely working with them in figuring out how stuff works, what works, what doesn't work, because no one's doing No one else is doing what we're doing.
[00:47:06] They have found what we've been working on super interesting, which is why they've allowed us to do so much, like, interesting stuff. Working with John, I mean, I had a really good conversation with John yesterday. We had a little brainstorm after the video we shot. And one of the things you mentioned, the billions of tokens, one of the things we've noticed, and it's actually a very interesting problem for them as well, when you're
[00:47:28] How big your peft adapter, your lore adapter is going to be in some way and like figuring that out is actually a really interesting problem because if you make it too big and because they support data sets that are so small, you can put like 20 examples through it or something like that, like if you had a really sparse, large adapter, you're not going to get any signal in that at all.
[00:47:44] So they have to dynamically size these things and there is an upper bound and actually we use. Models that are larger than what's publicly available. It's not publicly available yet, but when this goes out, it will be. But we have larger law adapters available to us, just because the amount of data that we're pumping through it.
[00:48:01] And at that point, you start seeing really Interesting other things like you have to change your learning rate schedule and do all these different things that you don't have to do when you're on the smaller end of things. So working with that team is such a privilege because obviously they're like at the top of their field in, you know, in the fine tuning space.
[00:48:18] So we're, as we learn stuff, they're learning stuff. And one of the things that I think really catalyzed this relationship is when we first started working on Genie, like I delivered them a presentation, which will eventually become the blog post that you'll love to read soon. The information I gave them there I think is what showed them like, oh wow, okay, these guys are really like pushing the boundaries of what we can do here.
[00:48:38] And truthfully, our data set, we view our data set right now as very small. It's like the minimum that we're able to afford, literally afford right now to be able to produce a product like this. And it's only going to get bigger. So yesterday while I was in their offices, I was basically, so we were planning, we were like, okay, how, this is where we're going in the next six to 12 months.
[00:48:57] Like we're, Putting our foot on the gas here, because this clearly works. Like I've demonstrated this is a good, you know, the best approach so far. And I want to see where it can go. I want to see what the scaling laws like for the data. And at the moment, like, it's hard to figure that out because you don't know when you're running into like saturating a PEFT adapter, as opposed to actually like, is this the model's limit?
[00:49:15] Like, where is that? So finding all that stuff out is the work we're actively doing with them. And yeah, it's, it's going to get more and more collaborative over the next few weeks as we, as we explore like larger adapters, pre training extension, different things like that.
[00:49:27] swyx: Awesome. I also wanted to talk briefly about the synthetic data process.
[00:49:32] Synthetic Code Data
[00:49:32] swyx: One of your core insights was that the vast majority of the time, the code that is published by a human is encrypted. In a working state. And actually you need to fine tune on non working code. So just, yeah, take us through that inspiration. How many rounds, uh, did you, did you do? Yeah, I mean, uh,
[00:49:47] Alistair Pullen: it might, it might be generous to say that the vast majority of code is in a working state.
[00:49:51] I don't know if I don't know if I believe that. I was like, that's very nice of you to say that my code works. Certainly, it's not true for me. No, I think that so yeah, no, but it was you're right. It's an interesting problem. And what we saw was when we didn't do that, obviously, we'll just hope you have to basically like one shot the answer.
[00:50:07] Because after that, it's like, well, I've never seen iteration before. How am I supposed to figure out how this works? So what the what you're alluding to there is like the self improvement loop that we started working on. And that was in sort of two parts, we synthetically generated runtime errors. Where we would intentionally mess with the AST to make stuff not work, or index out of bounds, or refer to a variable that doesn't exist, or errors that the foundational models just make sometimes that you can't really avoid, you can't expect it to be perfect.
[00:50:39] So we threw some of those in with a, with a, with a probability of happening and on the self improvement side, I spoke about this in the, in the blog post, essentially the idea is that you generate your data in sort of batches. First batch is like perfect, like one example, like here's the problem, here's the answer, go, train the model on it.
[00:50:57] And then for the second batch, you then take the model that you trained before that can look like one commit into the future, and then you let it have the first attempt at solving the problem. And hopefully it gets it wrong, and if it gets it wrong, then you have, like, okay, now the codebase is in this incorrect state, but I know what the correct state is, so I can do some diffing, essentially, to figure out how do I get the state that it's in now to the state that I want it in, and then you can train the model to then produce that diff next, and so on, and so on, and so on, so the model can then learn, and also reason as to why it needs to make these changes, to be able to learn how to, like, learn, like, solve problems iteratively and learn from its mistakes and stuff like that.
[00:51:35] Alessio: And you picked the size of the data set just based on how much money you could spend generating it. Maybe you think you could just make more and get better results. How, what
[00:51:42] Alistair Pullen: multiple of my monthly burn do I spend doing this? Yeah. Basically it was, it was very much related to Yeah. Just like capital and um, yes, with any luck that that will be alleviated to
[00:51:53] swyx: very soon.
[00:51:54] Alistair Pullen: Yeah.
[00:51:54] SynData in Llama 3
[00:51:54] swyx: Yeah. I like drawing references to other things that are happening in, in the, in the wild. So, 'cause we only get to release this podcast once a week. Mm-Hmm. , the LAMA three paper also had some really interesting. Thoughts on synthetic data for code? I don't know if you have reviewed that. I'll highlight the back translation section.
[00:52:11] Because one of your dataset focuses is updating documentation. I think that translation between natural language, English versus code, and back and forth, I think is actually a really ripe source of synthetic data. And Llama3 specifically called out that they trained on that. We should have gone more into that in our podcast with them, but we, uh, we didn't, we didn't know, but, uh, there's a lot of interesting work on synthetic data stuff.
[00:52:33] SWE-Bench Submission Process
[00:52:33] swyx: We do have to wrap up soon, but I'm going to briefly touch on the submission process for SuiteBench. So, you have a 30 percent state of the art SuiteBench result, but it's not on the leaderboard because of submission issues. I don't know if you want to comment on, on, like, that stuff versus, uh, you know, we also have, like, we also want to talk about SuiteBench verified.
[00:52:51] Um, yeah, just anything on the benchmarking side. The potted
[00:52:55] Alistair Pullen: history of this is, is, is quite simple, actually. SweeBench, up until, I want to say two weeks ago, but it might be less than that, or more than that. But I think two weeks ago, suddenly started mandating what they call trajectories, when you submit.
[00:53:08] So, but prior to this, essentially, when you run SweeBench, you run it through their harness, and out the other end you get a report. json, which is like, here's how many I resolved, here's how many I didn't resolve, these are the IDs, the ones I did, these ones the IDs I didn't, and it gives you any ones that might, might have errored, or something like that.
[00:53:22] And what you would submit would be all of your model patches that you outputted and that report. And then you would like PR that into the sweep entry per and that would be it. That was the still the case when we made our submission on whatever day it was. They look at them every Monday. We submitted it at some point during the week.
[00:53:40] I want to say it was for four days before that. And, um, I sort of like sat back and waited. I assumed it would be fine when it came to Monday. Um, they then said, actually, no, we want model trajectories. And I was like, okay, let me see what this is. And so on. I sort of dug into it and like model the trajectories are essentially the context window or like the reasoning process of like, show you're working.
[00:54:03] How did you get here? If you do a math exam, show me you're working. Whereas before they were like, just give me the final answer. Now they want to see the working, which I completely understand why they want to see that. Like the SWE bench fundamentally is an academic research project and they want all the stuff to be open source and public so people can learn from each other and improve and so on and on.
[00:54:20] Very good. I completely agree. However, at least for us, and the reason that we are not on the leaderboard is that obviously the model outputs that we generate are sort of a mirror of our training data set, right? Like you train the model to do a certain thing and output a certain way. Whatever your output looks like, your training data for the moment, as a closed source company, like fighting for an Edge, we've decided not to publish that information for that exact reason.
[00:54:44] I don't want someone basically taking my tra. And then taking a model that's soon going to be GA and just distilling it immediately and then having genie for themselves. And, you know, as a business owner, that's the decision I've had to make. The patches are still public. So like the, dare I say, traditional SweeBench submission, you can go to our GitHub repo and see it and run them for yourself and verify that the numbers come out correctly.
[00:55:06] Like that is all, that is the potted reason. That's the story. That's the story. Uh, SweeBench verified. You have a score. I do have a score. I do have a score. 43. 8%? It's one of those things where like there aren't that many people on the leaderboard yet, so you don't know how good or bad that is. And it's smaller data set, right?
[00:55:22] Oh, it's, it's great. So on a tangent, Swebench, original Swebench was 2, 294. Which is expensive. It's like 8, 000 to run. Oh, that's cheap. That's cheap, what are you talking about? I don't know, at least for us, I don't even want to say publicly how much it cost us. How much it cost us to run that thing.
[00:55:42] Expensive, slow, really like crap for iteration, because like, you know, you make a change to your model, how does it do on SweetBench? I guess that's why SweetBench Lite existed, but SweetBench Lite was not a It was, it was easy stuff, right? It wasn't a comprehensive measure of the overall thing. So we actually had the idea a month ago to, what we were going to call SweeBench Small, where we were going to try to map out across SweeBench, like, what is the distribution of, like, problem difficulty and all these different things, and try to come up with, like, 300 examples that sort of map that, where, you know, Given a score on SWE Bench more, you could then predict your SWE Bench large score and sort of go from there.
[00:56:17] Fortunately, OpenAI did that for us, and probably much better than we would have done. They used some human labelers, and as obviously we're working with OpenAI quite closely, they talked to us about it, and they, Um, you know, we're able to let us know what the instance ID were, IDs were that were in the, the new suite bench version.
[00:56:36] And then as soon as I had that, I could just take the report from the one that I'd run and just diff them. And I was like, Oh, we got 219 out of 500, which is 43. 8%, which is to my knowledge, at least right now, state of the art also, which makes sense. But also GPT 4. 0 gets, I believe, 33%, which is like, I double checked that.
[00:56:58] The August one, the new one. Yeah, it's in their blog post. I can't remember which one it was. I don't know what the model version was. But, GPT 4, I believe, gets 33%. Which is, obviously, significantly better than what it got on the, um, original. Like, Sweebench, Sweebench, Sweebench. 2%! Yeah, yeah, yeah,
[00:57:14] swyx: exactly.
[00:57:15] Alistair Pullen: Something ridiculously low. But no, Sweebench verified, like, It's so good. It's like it's smaller. We know that the problems are solvable. It's not gonna cost me a lot of money to run it. It keeps my iteration time, you know, lower. And there are also some things that we are gonna start to do internally when we run SW bench to have more of an idea of how right our model is.
[00:57:37] So one of the things I was talking to John about yesterday was, sweet bench is a parcel or fail, right? Like you, you, you either have solved the problem where you haven't. is quite sparse, like it doesn't give you a huge amount of information because your model could have got a lot of it right, like looking through when you do a math paper, you could have got the reason, you know, you're working right until like the penultimate step, and then you get it wrong.
[00:57:55] So we're gonna look into ways of measuring, okay, well, your model got it right up to this line, and then it diverged. Um, and that's super easy to do because obviously, you know the correct state of all those questions. So I think one of the ways we're going to keep improving Genie is by going more in depth and saying, Okay, for the ones that failed, was it right at any point?
[00:58:15] Where did it go wrong? How did it go wrong? And then sort of trying to triage those sorts of issues.
[00:58:20] Future Plans
[00:58:20] swyx: So future plans, you have mentioned context sustaining an open source model. But basically, I think, you know, what the Genie is, is basically this, like, proprietary fine tuned data set and process and software that you can add onto any model.
[00:58:31] Is that the pen? That's the, that's the, the next year is gonna just be doing that. That is,
[00:58:34] Alistair Pullen: we're gonna, we're gonna get really, we're gonna be the best in the world at doing that. Um, and continue being the best in the world at doing that. And throwing it as many models as we can. Um, seeing what the performance is like and seeing what things improve performance in what places.
[00:58:47] Um, and also making the data set larger is like one of the biggest things we're gonna be working on.
[00:58:52] swyx: I think one of the decisions before you as a CEO is how much you have like the house model be like the one true thing, and then how much you spend time working on customer models.
[00:59:03] Alistair Pullen: That's the thing that really gets me so excited, genuinely.
[00:59:06] Like, we have a version of Genie. That we named after one of our employees. It's called the John. We have a version of Genie that is fine tuned on our code base. So we basically, it's the base, base Genie. And then we run the same data pipeline that we run on, like, all the stuff that we did to generate the main data set on our repo.
[00:59:27] And then all of a sudden you have, like, something that is both very good at software engineering, but is also extremely good at your repo. And that is phenomenal to use. Like, it's really cool.
[00:59:36] Ecosystem Trends
[00:59:36] Alistair Pullen: More
[00:59:37] swyx: broadly, outside of Cosign, what are you seeing? What trends are you seeing that you're really excited by?
[00:59:42] Who's doing great work that you want to
[00:59:44] Alistair Pullen: call out? One of the ones that, I mean, it's not an original choice, but Cursor are absolutely killing it. All the employees at Cosign love using it. And it's a really, really good example of, like, just getting, like, UX right, basically. Like, putting the LLM in the right place, and letting it allow you, and getting out of the way when you don't want it there, and making it familiar, because it's still VS Code, and all these things.
[01:00:08] They've, yeah, they've done an amazing job, and I think they just raised a round, so congrats they're doing amazing work.
[01:00:14] swyx: The decision to fork VS Code, I think, was controversial. You guys started as a VS Code extension. We did, yeah. Many, many, many people did that, and they did the one thing that No one wanted to do the
[01:00:22] Alistair Pullen: bravery.
[01:00:23] Honestly, I commend the bravery because like in hindsight, obviously it's paid off, but at least for me in the moment, I was one of those people being like, is that the people going to do that? Are people going to download that? And yes, obviously they are like, sure, doing the hard thing, which is having worked on genie recent, you know, for the past eight months or whatever, as taxing as it's been on us, like one of the main things I have learned from this is like, No matter how small you are, how much resource you have, just like try to do the hard thing because I think it has the biggest payoff.
[01:00:55] Founder Lessons
[01:00:55] swyx: More broadly, just like, uh, lessons that you've learned running your company.
[01:01:00] Alistair Pullen: Oh, it's been a two year journey. Two year journey. Um, I mean, it's better than any real job you can ever get. Like, I feel so lucky to be Working in this area, like, especially, you know, it was so validating to hear it from the guys at OpenAI as well, telling us like, we're on the cutting edge on the back.
[01:01:17] We're pushing the boundaries of what's possible with what we're doing. Because like, I get to do, I get to be paid to do this. You know, I have briefly, as you heard at the beginning, done real jobs and normal stuff. And like, just being able to do this on the daily, it's so interesting and so cool. It's like, I pinch myself a lot, genuinely, about the fact that I can do this.
[01:01:36] And also that not only I can do this, but Fortunately, being a co founder of the company, I have a huge amount of say as to where we go next. And that is a big responsibility, but it's also so exciting to me. Cause I'm like, you know, steering the ship is, has been really interesting so far. And I like to think that we've got it right, you know, in the last, in the last sort of eight months or so.
[01:01:54] Uh, and that this is like really the starting point of something massive to come.
[01:01:58] Hiring & Customers
[01:01:58] swyx: Awesome. Calls to action. Uh, I assume you're hiring. I assume you're also looking for customers. What's the ideal customer, ideal employee?
[01:02:07] Alistair Pullen: On the customer side. Honestly, people who are just willing to try something new, like the Genie UX is, is different to a conventional IDE, give it a chance, like that what we really do believe in this whole idea of like developers work is going to be abstracted, you know, levels higher than just the code, we still let you touch the code, we still want you to dive into the code if you need to, but Fundamentally, we think that if you're trying to offload the coding to a model, the model should do the coding and you should be in charge of guiding the model.
[01:02:34] So people who are willing to give something new a chance. Size of company and honestly, well, preferably the languages that are the most represented in our, in our training. So like anyway, if you're like doing TypeScript, JavaScript, Python, Java, that sort of thing. And in terms of size of company, like, so long as you're willing to try it, um, and there aren't any massive, like, infosec things that get in the way, like, it doesn't really matter.
[01:02:57] Like, code base size can be arbitrary for us. We can deal with any code base size, and essentially any language, but your mileage may vary. But for the most part, like, anyone who's willing to give it a try is the ideal customer. And on the employee front end, you're Honestly, we just want people who, um, we're going to be hiring both on like what we call like the traditional tech side.
[01:03:16] So like building the product essentially, and also hiring really heavily on the AI machine learning, um, data set side as well. And in both cases, essentially what we just wanted, like really passionate people who are obsessed with something and are really passionate about something and are willing to. It sounds so corny, but like, join us in what we're trying to do.
[01:03:39] Like, we have a very big ambition and we're biting off a very large problem here. And people who can look at what we've done so far and be like, wow, that's really impressive. I want to do that kind of work. I want to be pushing the boundaries. I want to be dealing with experimental stuff all the time. But at the same time, be putting it in people's hands and shipping it to people and so on.
[01:03:58] So if that sounds, you know, amenable to anyone, that's the kind of person we're looking to apply.
[01:04:02] swyx: Excellent. Any last words, any Trump impressions that you, did you like the
[01:04:07] Alistair Pullen: Trump impression? Everyone loved the Trump impression. Yeah. I mean, it's funny. Cause like I, I, I have some bloopers. I'll show you the bloopers after we finished recording.
[01:04:15] I'll probably tweet them at some point. The initial cut of that video had me doing a Trump impression. I sort of sat down into the chair and be like, Cosine is the most tremendous AI lab in the world. Unbelievable. I walked in here and I said, wow, this is an amazing lab. And like, we sent it to some of our friends and they were like.
[01:04:32] Nah, you can't cold open with Trump, man. You just can't. Like, no one knows who you are. You can end with it. But you can end with it. Now that that has gone out, we can now um, we can now post the rest of the bloopers, which are essentially me just like, fluffing my lines the entire time and screaming at my co founder out of frustration.
[01:04:48] So, yeah. Well,
[01:04:49] swyx: it was very well executed. Uh, actually, very few people do the contrary that you did. I'm, as a sort of developer relations person, I'm actually excited by that stuff. But, um, well, thank you for coming on. Very, very short notice. I hope you have a safe flight back and I'm excited to see. The full launch.
[01:05:03] Um, I think this is a super fruitful area and, uh, congrats on your launch. Thank you so much for having me. Cheers.
1
A tricky issue we discuss near the end of the pod; Genie is NOT recognized on the official SWE-Bench Leaderboard because of new submission requirements. Cognition Devin is also no longer on this leaderboard.
86 حلقات



